Open ML News - Holidays Edition
Your ML news from Dec 20 to Jan 4

Hi! 🦙 I’m Omar (ex-Hugging Face, now Google), and I'm passionate about staying on top of recent ML news, open model releases, and new tools. My goal with this weekly series is to summarize the most interesting things happening out there while distilling the highest value resources for you. Enjoy the roundup! If you like this content or have any feedback/suggestions, please let me know (X, bsky, LinkedIn)
New Models
2 OLMo 2 Furious: AllenAI has released the OLMo 2 Technical Report, including an update to their post-trained models that fixes a pre-tokenization mismatch. This paper dives deeply into pretraining stability, mid-training recipes, post-training, and infrastructure (including WandB logs!). The project is very transparent, sharing training code, data, evaluation, and infrastructure details. (paper, web demo)
Qwen QVQ: The Qwen team closed 2024 shipping an experimental 72B model for visual reasoning. "Experimental" here means it's still under development and may exhibit unexpected behavior. While it has some limitations, such as mixing languages and exhibiting circular logic patterns (where the reasoning loops back on itself), the improvements over the original Qwen2-VL 72B model are quite impressive on image reasoning benchmarks like MathVista and MathVision. (blog, web demo)
InternVL2.5-MPO: This vision LLM introduces a new technique called Mixed Preference Optimization (MPO), which combines preference optimization and supervised fine-tuning to boost reasoning abilities. The authors propose an automated pipeline to create large-scale, high-quality reasoning preference dataset. The model has clear improvements in reasoning and VQA benchmarks, with solid results for the models’ size. (models, paper, dataset)


ModernBert Embed: A few weeks ago, Answer.AI and LightOn released ModernBERT, a significant improvement over the original BERT from 2018. It’s faster, more accurate, trained with code, and handles a much longer context length (8k tokens vs 512). Encoder-based models like BERT are still widely used for various tasks, including creating embedding models. Embeddings are essential as they can capture semantic meaning (when you hear about vector databases and RAGs, embedding models are under the hood!). Since ModernBert release, I’ve been waiting for its first embedding fine-tune, and Nomic just delivered! (model, X thread)
YuLan-Mini: This 2.4B base models (with instruct coming soon) that have some interesting features. Even though it was trained on only 1T tokens, its benchmark results, especially in math and code, seem to surpass other models trained with significant more data. The report and model card are quite transparent with intermediate checkpoints, list of open datasets used, and their pretraining pipeline, which is designed to be data-efficient. (paper, models)
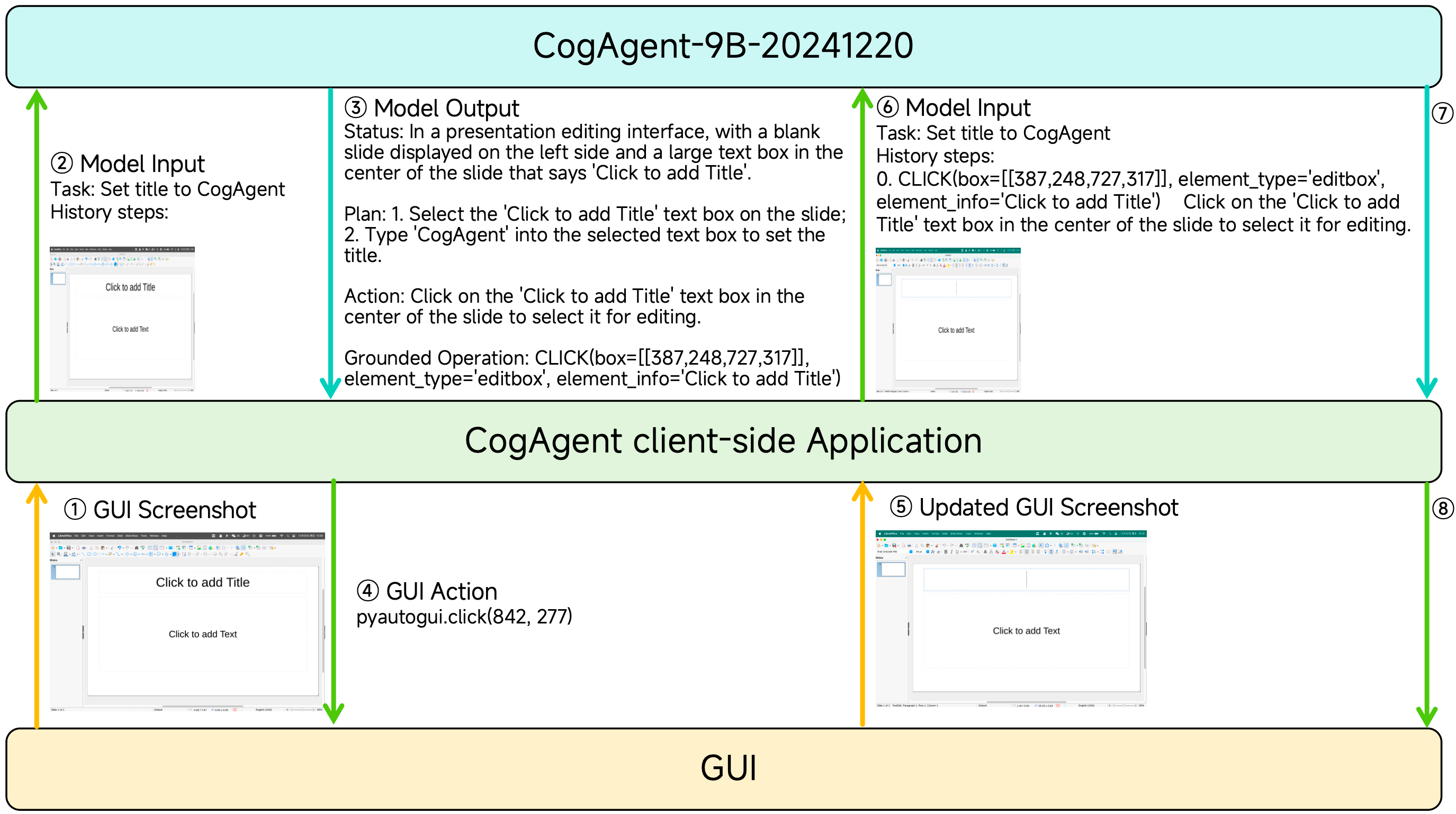
CogAgent-9B-20241220: This bilingual (Chinese/English) VLM model accepts screenshots and natural language commands, making it a powerful tool for creating GUI agents. GUI agents are programs that can interact with graphical user interfaces, automating tasks that would typically require human interaction. The initial 2023 release of CogAgent was impactful, so this iteration is exciting. Changes include a more powerful base model, improved GUI instruction datasets, refined post-training, a more granular Chain of Thought (CoT) process, and a more constrained action space. (blog, paper, model)
As a not so minor note, there’s been lots of anti China AI discourse saying Qwen is the only contributor. Note how from the list above, the following institutions are represented: Qwen (Alibaba), OpenGVLab, Shanghai AI Laboratory, Fudan University, Nanjing University, Chinese University of Hong Kong, Tsinghua University, SenseTime Research, and Renmin University of China. The China-backed ML ecosystem is really large and contributing to open ML.
New Datasets
Multimodal Textbook: This dataset contains 6.5M images interleaving text extracted from instructional videos (22,000 class hours). (code, dataset, paper)
CodeElo: Developed by Qwen, CodeElo is a standardized competition-level code benchmark with a reliable Elo rating calculation, which tells relative skill levels of models.(dataset)
New Tools
smolagents: Hugging Face has released smolagents, a simple library for using agentic capabilities with language models. In essence, it allows you to define agents (programs where LLM outputs control the workflow) that write actions in code. This is more general and flexible than simply returning JSONs. Smolagents also offers safe code execution and integrations with various APIs and models, including popular ones like OpenAI's models and the Hugging Face ecosystem. (blog post)
Interesting Reads
ARC series (by Melanie Mitchell at AI: A Guide for Thinking Humans). The ARC Prize, a well-known understanding and reasoning challenge, has been a very difficult goal in the ML community. I've remained skeptical about whether solving this challenge truly demonstrates abstract reasoning. Just a few weeks ago, the ARC organizers announced that OpenAI models achieved 75.7% and 87.55%, results that are impressive and above the current SOTA. However, these results raise many questions about what they actually show. Nathan Lambert recommended a great series of short articles by Melanie Mitchell, which contextualizes the ARC challenge and these results. I recommend taking an hour to go through them; they help understand the challenge and temper some of the hype on social media:
Why the Abstraction and Reasoning Corpus is interesting and important for AI: introduces the ARC domain, core knowledge systems being tested, and challenges.
On the “ARC-AGI” $1 Million Reasoning Challenge: gives a high-level overview of ARC solutions, including some dive into brute forcing with domain specific search, and 2023 SOTA.
Did OpenAI Just Solve Abstract Reasoning?: the most relevant on the OpenAI results, this article provides hypotheses on OAI approach, assumptions wanted on ARC solutions, and implications of the results.
Write better code (by Max Woolf). This is a fun short read exploring what happens if you keep asking a LLM to write better code. This is similar to the image generation trend of “make it more X”, but applied for code.
GRPO summary (by Philipp Schmid). Group Relative Policy Optimization (GRPO) is a method introduced in the DeepSeekMath paper from early 2024 and used by DeepSeek and Qwen for post-training. Philipp's post is a nice high-level recap of the technique. While the number of different post-training optimization algorithms is becoming a bit overwhelming (we already had PPO, DPO, IPO and few others), GRPO seems to offer a valuable addition by focusing on relative improvements within groups of outputs. (X post, paper)
2024 AI Timeline (by Vaibhav Srivastav) is an amazing timeline of ML released in 2024.
Interesting Content I wish I had the Time to review
2.5 Years in Class: A Multimodal Textbook for Vision-Language Pretraining (paper)
Flash Attention derived and coded from first principles with Tritron (YouTube video). Almost 8 hours of content which seems to be of high quality.
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization (paper)
On working on AI and mental health
This week I received the news that Felix Hill passed away. This is a sad loss for everyone, and a reminder of the importance of stress working in AI, managing stress, and prioritizing mental health. We need an ecosystem with more collaboration, empathy, kindness, support, and friendship, and less toxic culture and egoism. If you ever feel lonely, please know you're not alone. Take care of yourself, and please reach out. We're here to support and help each other. If you need someone to talk to, don't hesitate to contact me or a mental health professional. Let's work together to build a healthier and more supportive AI community.